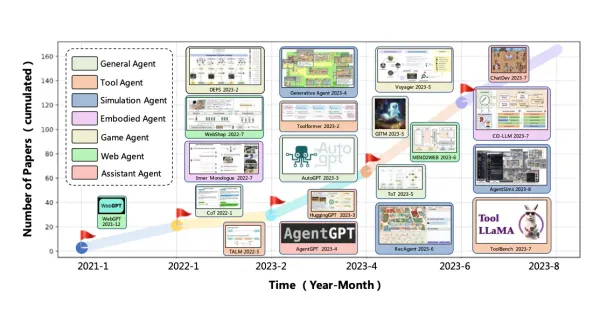
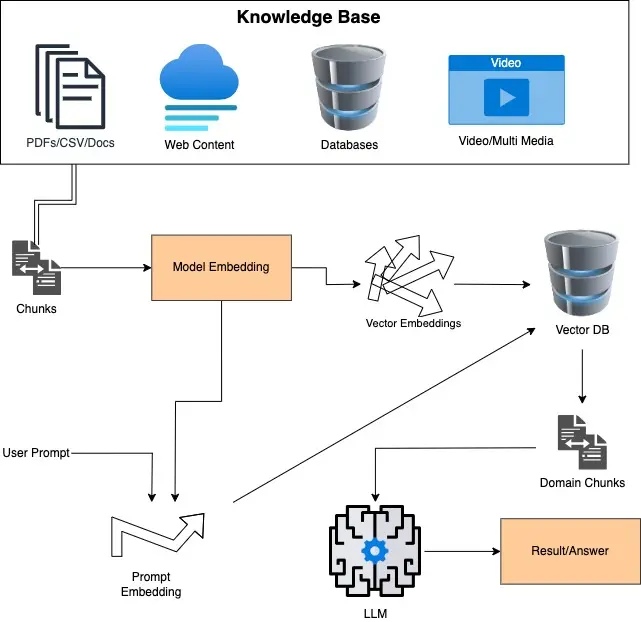
Architecture design of Domain Tuned Agents (LLM + RAG)

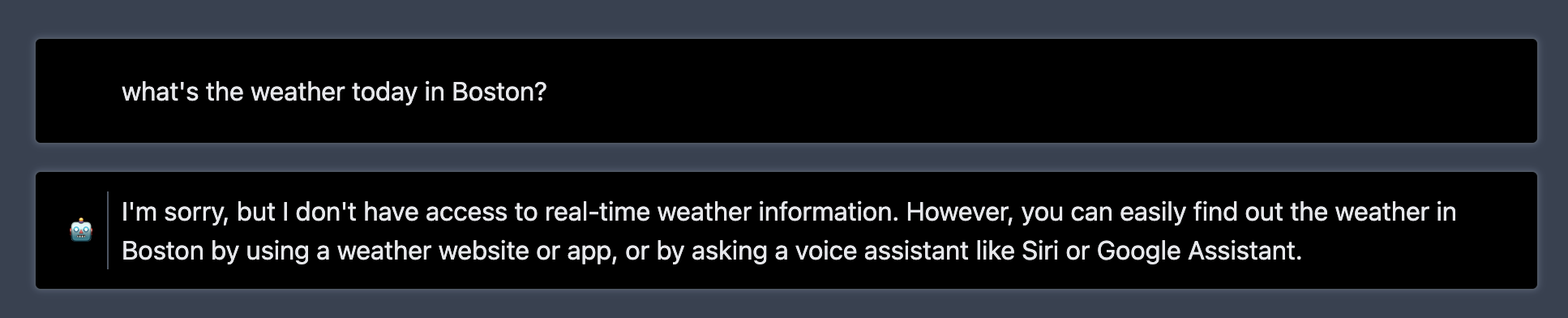
LLMs are limited to their generalized pre-training set, thus information and content related to anything current won't be answer or perhaps the model will attempt to hallucinate an answer. I'm sure you've gotten an answer such as this from querying bard or gpt.
This brings up an interesting challenge for enterprises and projects hoping to leverage these models for specific data and knowledge that's current. For these LLMs to be useful, they need access to real time data and knowledge, or even better simply centered/tuned for an understanding of specific domain/industry concepts. This behavior is possible to a degree using the context window, such as having your LLM model take the role of financial analyst and being fed role defining descriptions so as to tune the output based on the context. And perhaps even copy-pasting bits and pieces of a pdf or report to tune a model to that specific context will fit your use case. How ever, from a technical standpoint context windows are limited (anywhere from 500 words to 20,000 words). To help address this, agents can be tuned to varying degrees as mentioned in our previous post. In this post we'll go through our RAG implementation design for agent tuning.
Retrieval-Augmented Generation (RAG) agent architecture
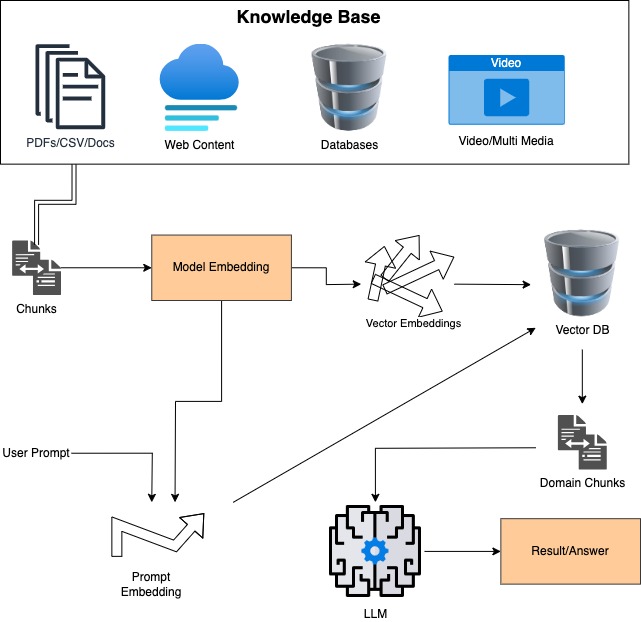
RAG, or Retrieval-Augmented Generation, is a system that uses a pipeline of software components to provide relevant information in response to prompts. The components of the RAG system include:
- Knowledge base (KB): This is where information is stored and can be easily read, modified, and replaced.
- Large language model (LLM): The LLM processes the prompt and generates a response.
- Embeddings: Embeddings are used to represent the information in the KB as vectors, making it easier to find relevant information.
- Vector database: The vector database stores these embeddings and uses them to quickly find relevant information when a prompt is received.
The RAG system works by vectorizing the Knowledge Base and using the vector database to find relevant information. This information is then combined with the prompt and sent to the LLM for processing. The LLM generates a response, which is then provided as the final output.
Case Study: Document Summarization/Generation
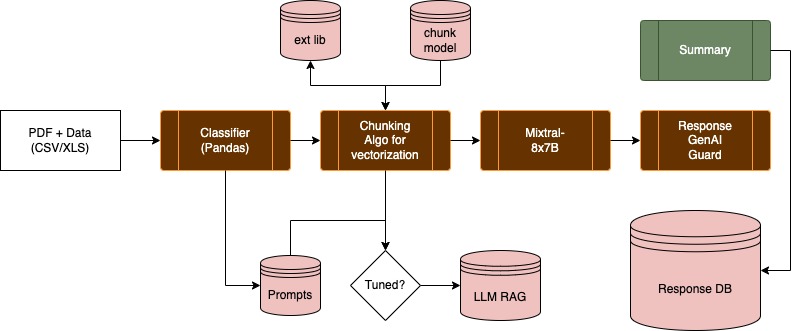
The above RAG implementation using mistral's mixtral of experts model (mixtral 8x7b), is an excellent way to quickly tune an agent to a context, in our case to a financial record reporting use case. Having data pulled in from specific sources allows the agent to generate contextually aware outputs. Meaning that report which required you to dig through 100+ pages and different data sets is preloaded into the model along with the ability for the agents to make note of which sources referenced.