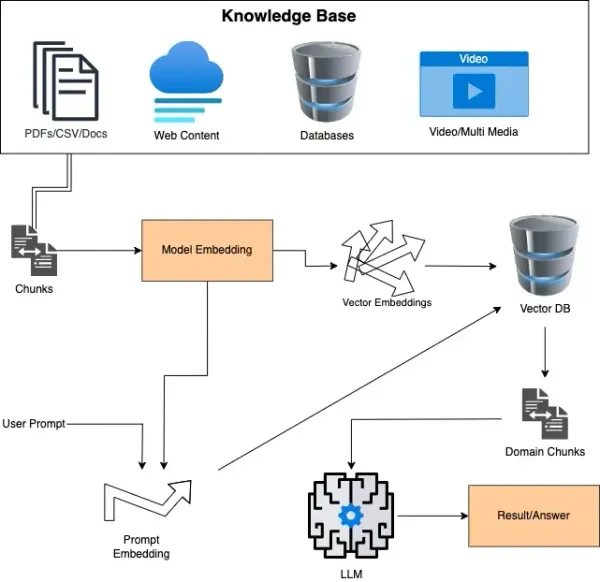
Our approach to developing LLM-powered autonomous agents

LLMs like ChatGPT, trained on extensive text data, excel in creative writing and summarization. Their deep language understanding and real-world knowledge enable them to handle tasks like reasoning, task planning, and decision-making, vital for autonomous agents. In this article we will highlight the increasing need for specializing LLMs for contextual awareness, crucial for nuanced B2B interactions. We discuss techniques to develop specialized, context-aware LLM-powered autonomous agents and explore real-world examples.
What is an LLM-Powered Autonomous Agent?
LLM-powered autonomous agent simply put is a piece of software (albeit advanced) that leverages the latest statistical methods (billions of parameters) along with a massive data set (petabytes). If we could simplify it further into some sort of word equation.
LLM-agent = code + statistics + data
These advanced large language models (LLMs) such as ChatGPT, LLama 2, PaLM 2. Are now standing out due to their ability to surpass human benchmarks on a range of professional and academic standards, such as the SATs. Thus, we can leverage them for generalized use cases such as:
Plan Tasks: Imagine them as intelligent assistants. You give them a complex task in simple language, and they can break it down into smaller steps, figure out the right order to do them, check their work, and keep improving until they achieve the goal accurately.
Utilize Tools: They can understand and use different software tools. This means selecting the appropriate digital tools for each task, interacting with other agents, connecting with online resources for information, or handling specific data processes correctly.
Adapt to Context: These agents are skilled at adjusting their actions based on the situation. They can change their approach based on the instructions you give them, or information they gather from external sources, making them flexible and responsive.
We'll need to further explore how we can make use of these state-of-the-art (SOTA) frameworks and techniques in creating LLM systems. This includes integrating proprietary data and processes to bolster LLMs' decision-making and task execution, ensuring efficient and accurate performance on industry context.
How to define Tasks
In the development of autonomous agents, a critical ability is to break down high-level instructions or goals into a sequence of logical tasks. This process involves various techniques, ranging from simple to complex, to ensure effective task decomposition.
Prompt engineering techniques
The most straightforward use of an LLM is Prompt engineering, the beauty is that specific contexts don't involve complicated infrastructure setups for training or tuning network weights at all. You design and refine your text input to a model to guide and influence the kind of output you want.
- Zero-shot prompting
- Few-shot prompting
- Chain-of-thought prompting
- Tree of Thoughts prompting
- ReAct* (our preferred prompting method)
Prompt engineering with external databases & caches (memory) techniques
The issue with prompt engineering is two fold. On one hand, LLM models are limited to the amount of tokens (words) that they're able to accept to properly contextualize a task. Typically context windows are between 1k-100k (newer models), a good understanding of context window sizing is that they're a double edged sword between performance and usability. It's important to keep in mind that a larger context window will be more expensive due to the heavy computational load required to sustain such a context window. And so on the other hand, how do you get an LLM to fetch knowledge that's unknown to the current environment, without paying an exorbitant amount? How best to incorporate massive data sets, such as internal technical documentation, CIMs, or proprietary company knowledge stores?
An elegant and yet effective solution to address contextual weaknesses, Retrieval Augmented Generation (RAG), introduced by Meta researchers, is a method that enhances Large Language Models (LLMs) by combining prompt engineering with fetching context from external data sources. This approach improves the model's performance and relevance, providing more accurate and context-aware responses.
Typically implementing RAG using a vector database/cache will solve the following concerns:
- Incorporates contextual private data without needing fine-tuning.
- Effectively broadens the range of information an LLM can process.
- Addresses the issue of hallucinations by referencing stored documents.
- As well as citing these documents in its responses, enhancing the model's explainability.
Parameter-efficient fine-tuning techniques
Parameter-efficient fine-tuning (PEFT) optimizes a pretrained model by adjusting only a few of its parameters. Since a large language model already knows a lot from its extensive training, it's often unnecessary and inefficient to tweak the entire model for specific tasks. Instead, fine-tuning is focused on a limited number of parameters. There are a number of techniques, however, we focus on the most effectively used in the ecosystem. In interest of brevity and accuracy it's best to review implementations from HF and Meta
Programmable & Fine-tuning techniques
Structured Input/Output. LLMs are user-friendly in part due to their natural language interfaces (prompts), and yet natural language isn't always suitable for explicitly enforced logic-related tasks. For most applications and processes, a more structured method might be more effective. This approach allows using the LLM at scale as part of a process while still leveraging the LLM's general reasoning capabilities for solving unstructured tasks. Notable examples and use cases for developers include:
- https://lmql.ai/ - Prompt construction and generation using Python's control flow and dynamic string interpolation.
- DSPy - A complete python based framework with its own compiler for bootstrapping prompts
References
- Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan (2023). "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." arXiv:2305.10601 [cs.CL]. https://arxiv.org/abs/2305.10601
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao (2022). "ReAct: Synergizing Reasoning and Acting in Language Models." arXiv:2210.03629 [cs.CL]. https://arxiv.org/abs/2210.03629
- Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom (2023). "Toolformer: Language Models Can Teach Themselves to Use Tools." arXiv:2302.04761 [cs.CL]. https://arxiv.org/abs/2302.04761
- Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen (2023). "A Survey on Large Language Model based Autonomous Agents." arXiv:2308.11432 [cs.AI]. https://arxiv.org/abs/2308.11432